
科技日报记者 张梦然
当地时间23日一场在线直播中,OpenAI团队揭开了首个AI智能体Operator的神秘面纱。这一创新成果打破了传统应用程序编程接口的限制,赋予了AI直接与图形用户界面交互的能力,就仿佛能像人类那样使用电脑,从而向实现通用人工智能迈进了一步。
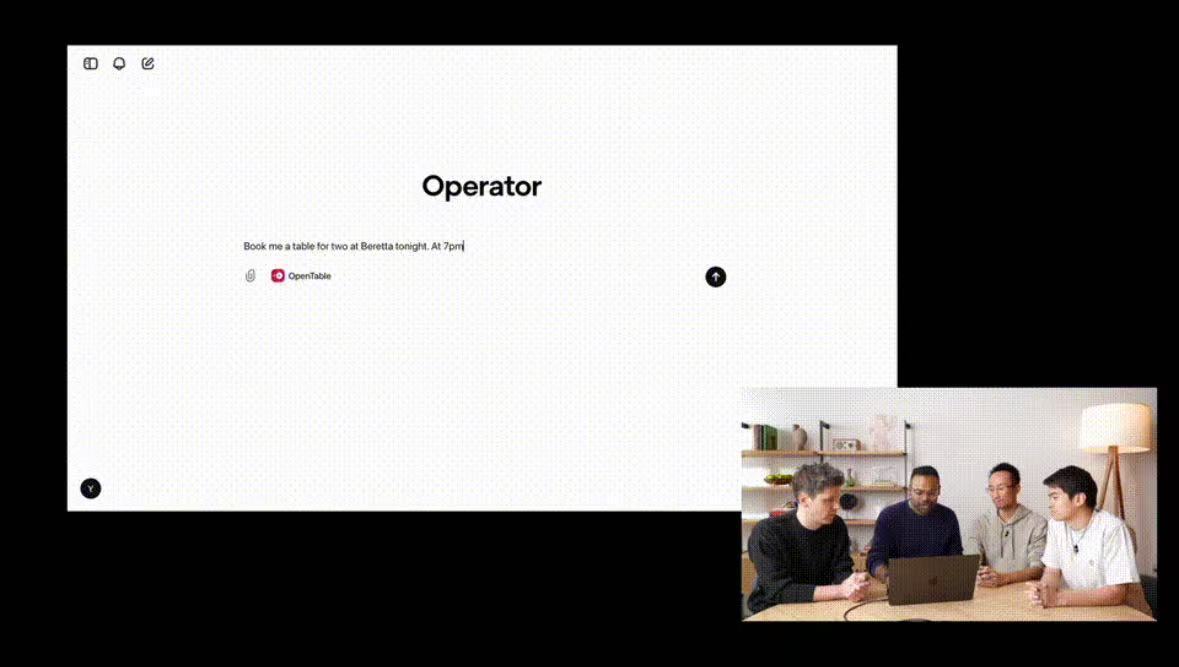
演示中,Operator展现了其强大的能力。它不仅能够精确理解指令,还能自主完成复杂任务,如自动填写在线表单、进行网购、创建表情包以及处理重复性浏览器任务等。这一切都是通过一个被称为CUA的新模型实现的。该模型结合了GPT-4o的视觉功能和高级推理技术,并通过强化学习不断优化自己的性能。
值得注意的是,在多个测试环境中,CUA模型的表现令人印象深刻。例如,在OSWORLD上执行计算机使用任务的成功率达到了38.1%,比之前最佳结果提高了近16%;而在WebArena上的成功率更是高达58.1%,提升了22%。尽管这些成绩与人类相比还有一定差距(人类分别为72.4%和78.2%),但CUA在某些特定场景下展示了惊人的效率,比如在网页代理WebVoyager平台上,达到了87%的成功率。
为确保安全性和用户体验,当Operator执行任务时,会采取行动、抓取屏幕截图并创建子计划,形成一个“观察—计划—执行”的闭环。此外,用户可以随时接管控制权,并且在接管期间的所有操作都不会被记录下来,以此保护隐私。即使遇到买错东西或订错酒店的情况,Operator也会在继续行动之前请求人类确认。
面对可能存在的风险,如诈骗网站,OpenAI引入了一个提示注入监视器,类似于防病毒软件的功能,可以在发现可疑行为时立即停止操作。这标志着L3级别的智能体时代正式到来,而OpenAI也重申了其对2025年的展望——这一年将是智能体之年。
随着Operator的发布,未来几个月内,人们或有望见证更多智能体的出现。它们将进一步扩展动作空间,适应更加广泛的应用场景,开启下一轮人机交互革命。目前,Operator仅限于美国的ChatGPT Pro(付费服务)用户试用,不过未来很快会向更多用户提供服务。
















