
科技日报记者 华凌
12月19日,智源研究院发布并解读国内外100余个开源和商业闭源的语言、视觉语言、文生图、文生视频、语音语言大模型综合及专项评测结果。

据悉,相较于今年5月的模型能力全方位评估,本次智源评测扩展、丰富、细化了任务解决能力内涵,新增数据处理、高级编程和工具调用的相关能力与任务;首次增加面向真实金融量化交易场景的应用能力评估,测量大模型的收益优化和性能优化等能力;首次探索基于模型辩论的对比评估方式,对模型的逻辑推理、观点理解、语言表达等核心能力进行深入分析。
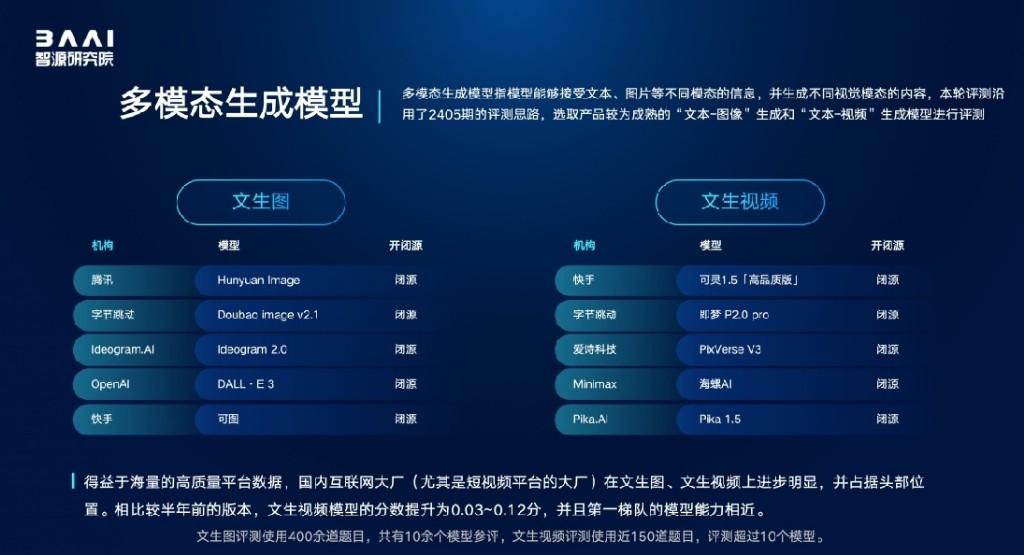
智源评测发现,2024年下半年大模型发展更聚焦综合能力提升与实际应用。多模态模型发展迅速,涌现不少新的厂商与新模型,语言模型发展相对放缓。模型开源生态中,除了持续坚定开源的海内外机构,还出现新的开源贡献者。
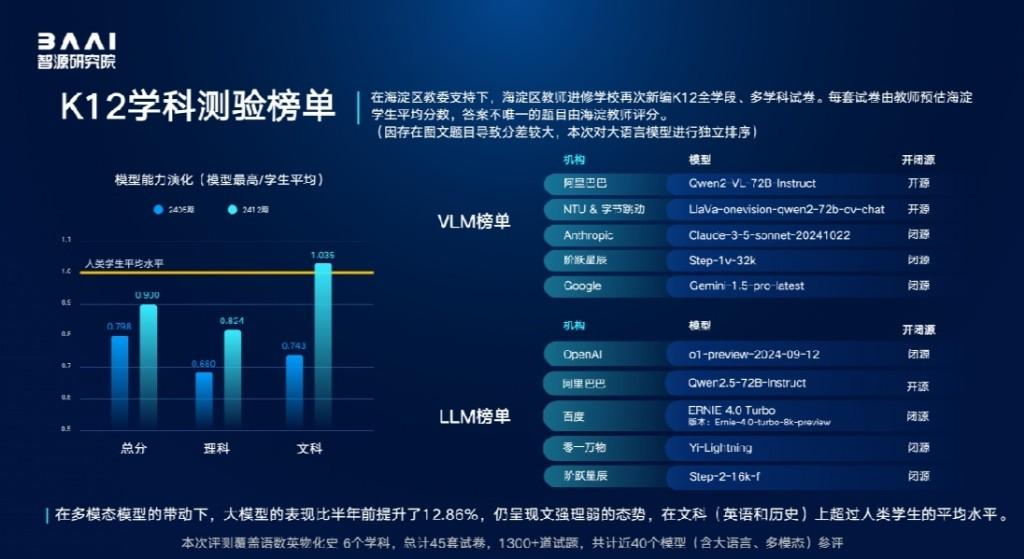
本次评测,智源研究院再次联合与海淀区教师进修学校新编K12全学段、多学科试卷,进一步考察大模型与人类学生的能力差异,其中,答案不唯一的主观题依然由海淀教师亲自评卷。得益于多模态能力的带动发展,模型本次K12学科测验综合得分相较于半年前提升12.86%,但是仍与海淀学生平均水平存在差距;在英语和历史文科试题的表现上,已有模型超越人类考生的平均分;模型普遍存在“文强理弱”的偏科情况。

FlagEval大模型角斗场,是智源研究院今年9月推出的面向用户开放的模型对战评测服务,以反映用户对模型的偏好。目前,FlagEval覆盖国内外约50款大模型,支持语言问答、多模态图文理解、文生图、文生视频四大任务的自定义在线或离线盲测。此次评测,共有29个语言模型、16个图文问答多模态模型、7个文生图模型、14个文生视频模型参评。评测发现,用户对模型的响应时间有更高要求,对模型输出的内容倾向于更结构化、标准化的格式。

智源研究院副院长兼总工程师林咏华在评测发布会上表示,FlagEval评测体系一直坚守科学、权威、公正、开放的准则,通过技术方法平台持续创新,打造丈量模型能力的标尺,为大模型技术生态发展提供洞察。2025年,FlagEval评测体系的发展将进一步探索动态评测与多任务能力评估体系,以评测为标尺感知大模型的发展趋势。
(智源研究院供图)
















